MapReduce is a high-level programming model and implementation for processing large scale parallel data.
Imaging you need to count the frequency of words across a tremendous amount of documents. It may take years to calculate the result on a single computer. In fact, you can slice all documents into small pieces of words and put all those small segments of documents into a word counting program, which is what we called Mapper. Lots of mappers run on different computational environment in parallel then output every word’s frequency. The next step is to shuffle all different word key pairs and load them onto adders, which is the reducer. Finally, we will get what we want.
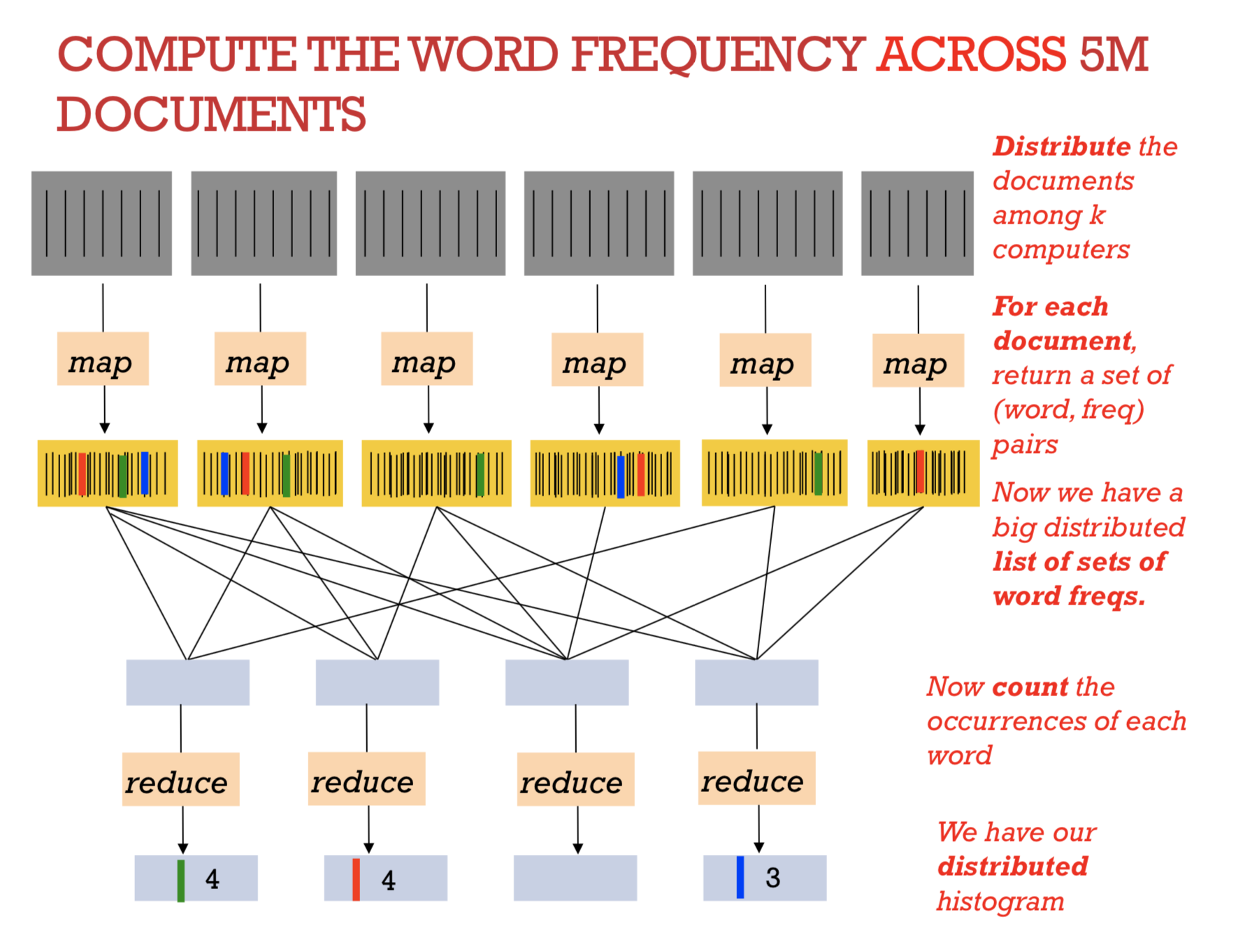
Implementation
There are 2 phase in MapReduce
Map Phase
User provides the MAP function:
Input: (input key, value)
Ouput: bag of (intermediate key, value)
System applies the map function in parallel to all (input key, value) pairs in the input file.
Reduce Phase
User provides the REDUCE function:
Input: (intermediate key, bag of values)
Output: bag of output (values)
The system will group all pairs with the same intermediate key, and passes the bag of values to the REDUCE function
Example: Matrix Multiply in MapReduce
A and B are matrix,
A has dimensions L,M,
B has dimensions M,N
Get output C = A * B
Solution
In the map phase
- for each element ( i , j ) of A, emit ( ( i , k ), A[ i , j ] ) for k in 1..N
- for each element ( j , k ) of B, emit ( ( i , k ), B[ j , k ] ) for i in 1..L
In the reduce phase, emit
- key = ( i , k )
- value = Sumj ( A [ i , j ] * B [ j , k ] )
test case
L = 3, M = 2, N = 2
In computer, it usaully input as a sequence of list [i, j, value]:
A: [1, 1, 1], [1, 2, 2], [2, 1, 3], [2, 2, 4], [3, 1, 5], [3, 2, 6]
B: [1, 2, 2], [2, 1, 3], [2, 2, 4]
Map Phase
| A | B | ||
|---|---|---|---|
| key (i, k) | value | key (i, k) | value () |
| (1,1) | [A(1, 1), 1] | (1,2) | [B(1, 2), 2] |
| (1,2) | [A(1, 1), 1] | (2,2) | [B(1, 2), 2] |
| (1,1) | [A(1, 2), 2] | (3,2) | [B(1, 2), 2] |
| (1,2) | [A(1, 2), 2] | (1,1) | [B(2, 1), 3] |
| (2,1) | [A(2, 1), 3] | (2,1) | [B(2, 1), 3] |
| (2,2) | [A(2, 1), 3] | (3,1) | [B(2, 1), 3] |
| (2,1) | [A(2, 2), 4] | (1,2) | [B(2, 2), 4] |
| (2,2) | [A(2, 2), 4] | (2,2) | [B(2, 2), 4] |
| (3,1) | [A(3, 1), 5] | (3,2) | [B(2, 2), 4] |
| (3,2) | [A(3, 1), 5] | (1, 1) | [B(1, 1), 0] |
| (3,1) | [A(3, 2), 6] | (2, 1) | [B(1, 1), 0] |
| (3,2) | [A(3, 2), 6] | (3, 1) | [B(1, 1), 0] |
Shuffle
| (1, 1) | [A(1, 1), 1] | [B(1, 1), 0] |
|---|---|---|
| [A(1, 2), 2] | [B(2, 1), 3] | |
| (1, 2) | [A(1, 1), 1] | [B(1, 2), 2] |
| [A(1, 2), 2] | [B(2, 2), 4] | |
| (2, 1) | [A(2, 1), 3] | [B(1, 1), 0] |
| [A(2, 2), 4] | [B(2, 1), 3] | |
| (2, 2) | [A(2, 1), 3] | [B(1, 2), 2] |
| [A(2, 2), 4] | [B(2, 2), 4] | |
| (3, 1) | [A(3, 1), 5] | [B(1, 1), 0] |
| [A(3, 2), 6] | [B(2, 1), 3] | |
| (3, 2) | [A(3, 1), 5] | [B(1, 2), 2] |
| [A(3, 2), 6] | [B(2, 2), 4] |
Reduce Phase
(1,1): 2 * 3 = 6
(1,2): 1 2 + 2 4 = 10
(2,1): 4 * 3 = 12
(2,2): 3 2 + 4 4 = 22
(3,1): 6 * 3 = 18
(3,2): 5 2 + 6 4 = 34
Application - Distributes File System(DFS)
- For very large files: TBs, PBs
- Each file is partitioned into chunks, typically 64MB
- Each chunk is replicated several times (≥3), on different racks, for fault tolerance
Implementations:
• Google’s DFS: GFS, proprietary • Hadoop’s DFS: HDFS, open source
Extensions & Contemporaries
- Pig: Relational Algebra over Hadoop
- HIVE: SQL over Hadoop
- Impala: SQL over HDFS (uses some HIVE code)
- Cascading: Relational Algebra
Something else
Finally complete the online course - Data Manipulation at Scale: Systems and Algorithms
Here’s my solution in mapreduce assignment (Week 3 assignment)
https://github.com/testsiling/Data-Science-at-Scale-Solution