Linear Regression
Linear regresssion with one variable.
Hypothesis:
Choose and so that is close to y for out training example(x,y)
Cost Function
m = number of training example.
h = my hypothesis
y = actual
Goal: minimize
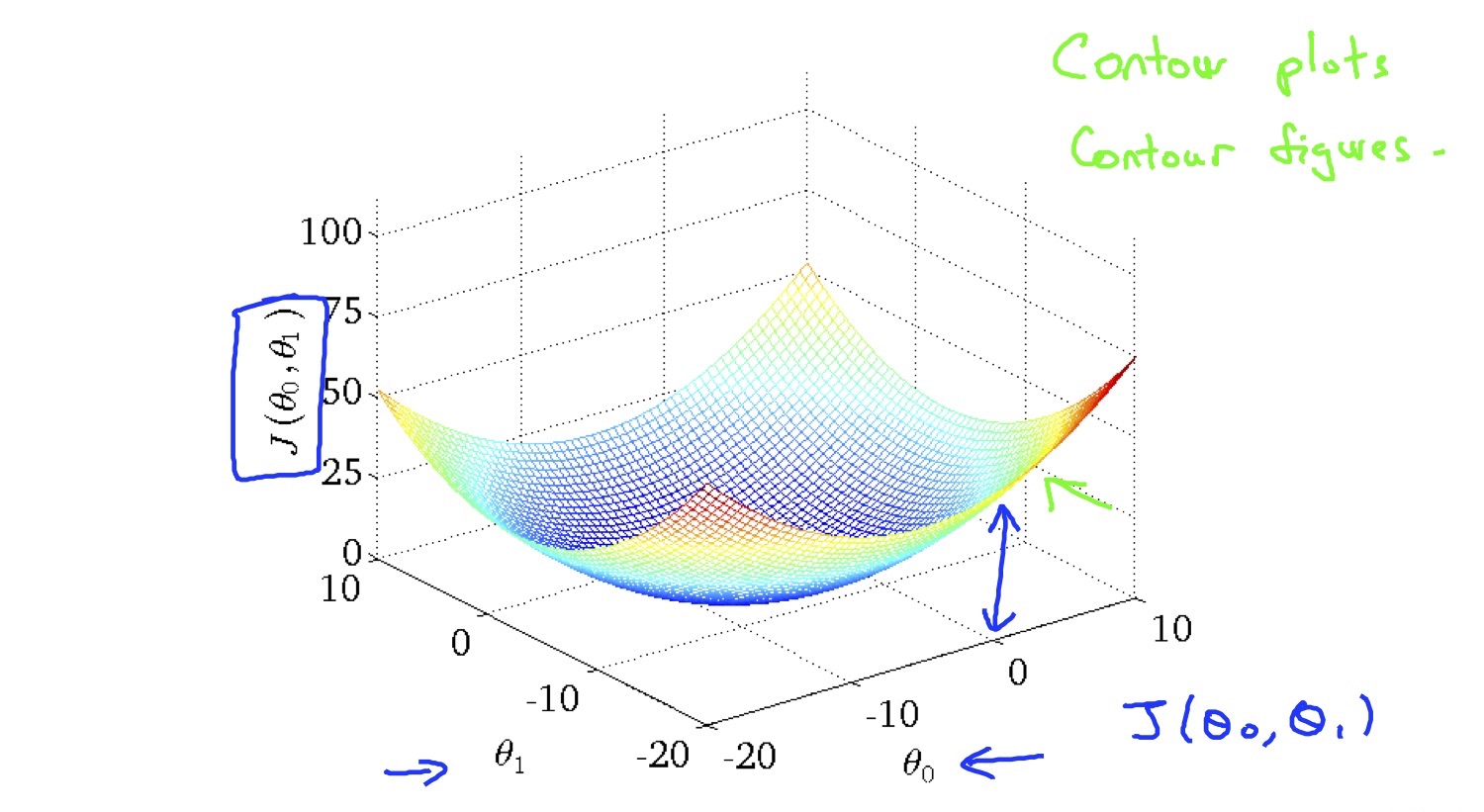
cost function look like this:
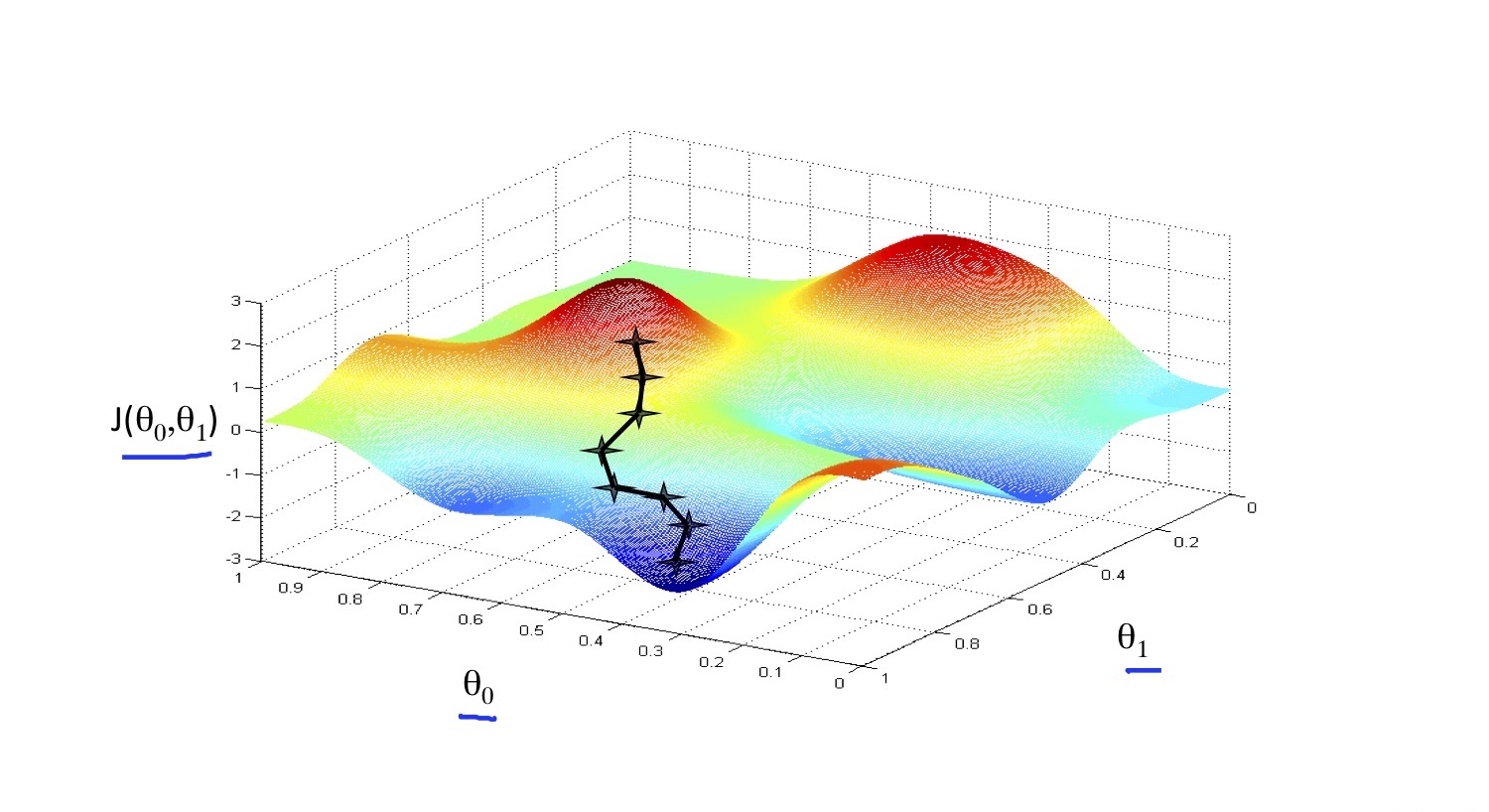
Gradient Descent
start with . Changing to reduce the , until we hopefully end up at a minimum.
α means learning rate. if α is too small, gradient descent can be slow, if α is too large, gradient descent can overshoot the minimum. It mat fail to converge.
Feature Scaling
Make sure features are on a similar scale, or else gradient descent will take a long time.
Processing every feature into approximately a [-1, 1] range. ( [-3, 3] might also works. )
Mean Normalization
Replace with
μ is average value of X
S is range ( max - min ), or standard deviation.
Learning Rate α
- if α is too small: slow canvergence
- if α is too large: may not decrease on every iteration, may not converge (miss the local optimum).
Hence, try α
0.001 -> 0.003 -> 0.01 -> 0.03 -> 0.1 -> 0.3 ….Normal Equation
Normal equation is a method to solve for θ analytically.
octave code: pinv(X’ * X) * X’ * y
If you use normal equation, you don’t need to do feature scaling actually.
The matrix transpose is very expensive needs . Therefore, if the n is large, might be greater than 10000, you should consider gradient descent.