Apriori Algorithm (Agrawal & Srikant, 1994) is one of scalable methods for mining frequent patterns.
It is a Candidate Generation and Test Approach
According to the downward closure property of frequent patterns: If there is any itemset which is infrequent, its superset should not be generated/tested (Apriori pruning principle)
Apriori Algorithm Example
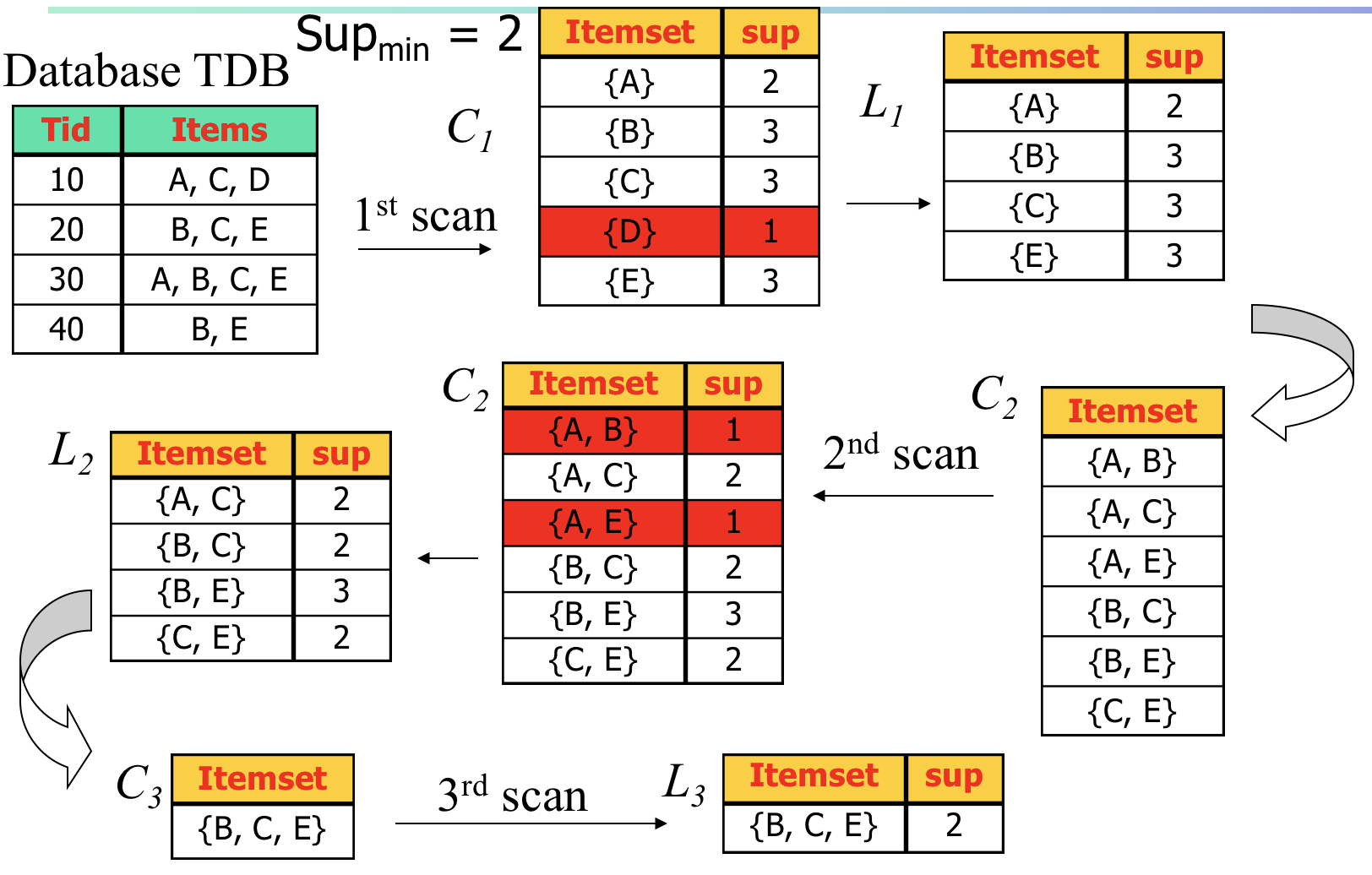
{B, C, E} is generated from {B, C} and {C, E}
{A, B, C}, {A, B, E}, {A, C, E} will bot be generated because {A, B} and {A, E} is not popular and have been removed from
: Candidate itemset of size k
: frequent itemset of size k
Challenges
- Multiple scans of transaction database (Slow, high cost)
- Huge number of candidates (a 2000 itemset might generate 200 popular rules.)
- Tedious workload of support counting for candidates.
Improvement
- Partition: Scan Database Only Twice (A. Savasere, E. Omiecinski, and S. Navathe. An efficient algorithm for mining association in large databases. In VLDB’95 )
- Hash: Reduce the Number of Candidates (J. Park, M. Chen, and P. Yu. An effective hash-based algorithm for mining association rules. In SIGMOD’95 )
- Sampling for Frequent Patterns (H. Toivonen. Sampling large databases for association rules. In VLDB’96 )
- DIC: Reduce Number of Scans (S. Brin R. Motwani, J. Ullman, and S. Tsur. Dynamic itemset counting and implication rules for market basket data. In SIGMOD’97 )
- FP-Growth